Đây là một phiên bản đóng gói, với chín lớp, trên các chip từ bộ xử lý 5nm và 7nm để sử dụng trên điện thoại di động và đám mây, cho đến các bộ gia tốc dành riêng cho ứng dụng tiêu thụ điện năng cực thấp dành cho thiết bị đeo được.
IBM và Samsung đều giới thiệu bộ xử lý ML cho điện thoại, trong đó xử lý AI cục bộ sẽ loại bỏ nhu cầu tham gia đám mây, miễn là các kiến trúc đủ mạnh và đủ linh hoạt để đối phó với khối lượng công việc đa dạng - có thể cấu hình lại để phù hợp với các mạng nơ-ron khác nhau một chút -chiều rộng, số lớp và các kích thước khác có sẵn cho chúng.
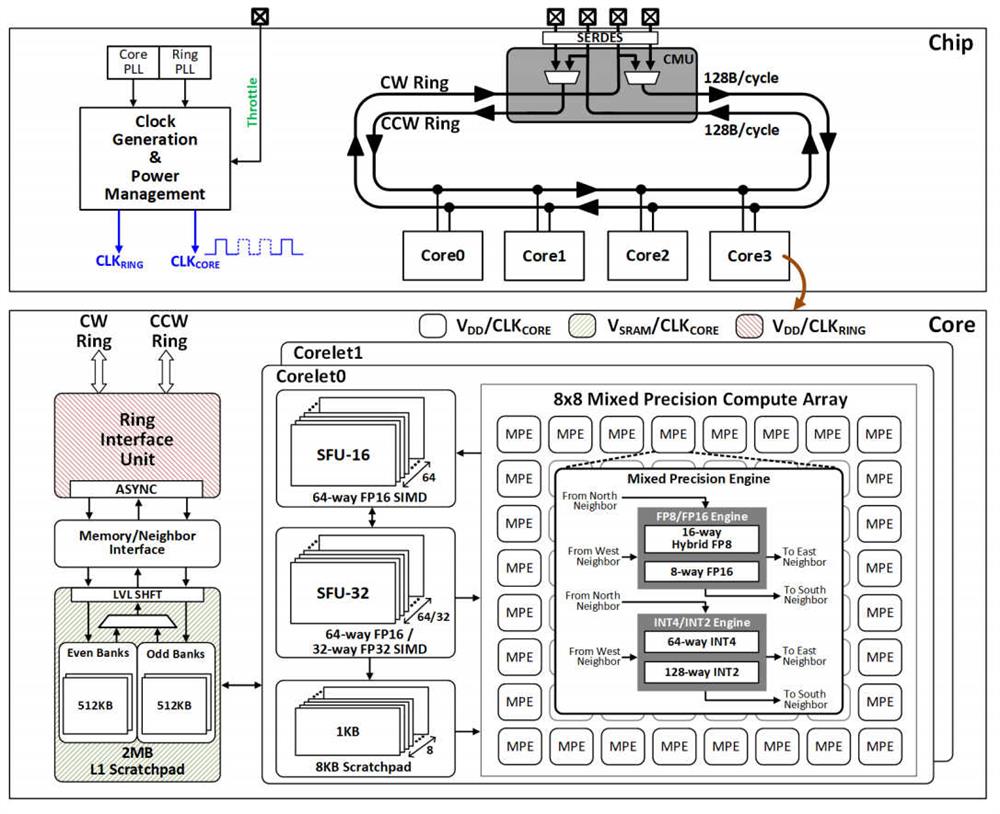
IBM’s là chip 4 nhân 7nm với 25,6Tflop / s khả dụng cho đào tạo FP8 ‘hybrid’ và 102,4Top / s cho hội nghị INT4 (xem sơ đồ).
Dấu phẩy động lai 8bit (HFP8) là một định dạng được phát minh tại IBM (được tiết lộ vào năm 2019) như một cách khắc phục những hạn chế của định dạng dấu phẩy động 8bit tiêu chuẩn (1 dấu, 5 số mũ, 2 phần định trị) FP8, hoạt động tốt khi đào tạo một số mạng nơ-ron tiêu chuẩn, nhưng dẫn đến độ chính xác kém khi đào tạo người khác. Hybrid FP8 sử dụng 4 số mũ và 3 bit phần định trị để truyền về phía trước, sau đó là 5 số mũ và 2 bit phần định trị để truyền ngược, tăng đáng kể độ chính xác của quá trình huấn luyện, theo công ty.
Bốn lõi được liên kết bằng một cặp vòng dữ liệu nhanh rộng, một để truyền theo chiều kim đồng hồ và một để truyền ngược chiều kim đồng hồ. Chúng có thể được đóng trong chip, hoặc được mở và định tuyến qua bộ nhớ ngoài hoặc nhiều chip giống hệt nhau để xử lý các mạng lớn hơn. Các vòng và lõi không đồng bộ để cho phép các tốc độ xung nhịp khác nhau trao đổi năng lượng cho hiệu suất một cách riêng biệt.
Mỗi lõi được chia thành hai lõi phụ dùng chung bộ nhớ bàn di chuột, sau đó mỗi lõi phụ có một mảng động cơ 8 × 8 được tối ưu hóa để tăng tốc tích chập và nhân ma trận với các đường ống riêng biệt để tính toán dấu phẩy động và điểm cố định - cùng cung cấp Khả năng FP16, HFP8, INT4 và INT2 cho cả đào tạo và suy luận AI.
Chip 36mm2 được sản xuất bằng cách sử dụng kỹ thuật in thạch bản EUV và đạt được các chỉ số hiệu suất ở trên với 0,75V trên lõi và 0,95V trên SRAM. Sử dụng kiến thức mạng thu thập được khi mạng được biên dịch, chip có thể điều chỉnh các lớp mạng ngốn điện để duy trì trong phạm vi ngân sách năng lượng. Hoạt động danh nghĩa (lõi 0,55V, 0,7V SRAM) mang lại xung nhịp 1GHz và duy trì 3,5Tflop / s / W FP8 và 16Top / s / W INT4.
Bộ xử lý AI di động của Samsung nhỏ hơn, với kích thước 5,46mm2 và sử dụng quy trình 5nm để triển khai tổng cộng ba lõi của nó và có thể thực hiện 623 suy luận/s.
Mỗi lõi có hai lõi phụ ('động cơ tích hợp') cùng với một đơn vị xử lý vectơ và 1Mbyte bàn di chuột. Mỗi lõi phụ có trọng số - bản đồ tính năng - tìm nạp tổng một phần và một mảng 1.024 MAC - vì vậy> 6.000 MAC trên chip). Nó có thể thực thi 64 sản phẩm chấm của vectơ 16 chiều trên mỗi chu kỳ. Bàn di chuột chứa tất cả các trọng số, bản đồ tính năng đầu vào, bản đồ tính năng đầu ra và tổng một phần cho một lớp hoặc, nếu lớp lớn để phù hợp cùng một lúc, hãy xếp chồng lên lớp đó. Một đơn vị xử lý vectơ thực hiện các chức năng phi tuyến tính phức tạp như chuẩn hóa và softmax.
Không giống như các bus vòng của IBM, các lõi trong trường hợp này được kết nối bằng một bus thông thường hơn sử dụng DMA (truy cập bộ nhớ trực tiếp).
Để tiết kiệm quá trình xử lý lãng phí và do đó, năng lượng, tính năng không bỏ qua bản đồ được triển khai. “Việc sử dụng MAC trên các lớp phức hợp trong Inception-V3 có thể được cải thiện trung bình 36% bằng tính năng không bỏ qua bản đồ tính năng,” theo bản trình bày của ISSCC. “Không giống như không bỏ qua trọng lượng, tính năng không bỏ qua bản đồ nâng cao hiệu suất hiệu quả và tiết kiệm năng lượng mà không cần bất kỳ bước đào tạo bổ sung nào như cắt giảm trọng lượng.
Con chip này chạy từ 550mV đến 900mV, và 332Mz đến 1.2GHz xung nhịp. Công suất và hiệu suất được đo trong khi chạy các lớp tích hợp, gộp và được kết nối đầy đủ của mẫu 8bit Inception-V3 mà không cần cắt bớt trọng lượng. Thông lượng suy luận tổng thể là 194 suy luận / s ở 332MHz và 623 suy luận / s ở 1.196GHz ở chế độ ưu tiên thông lượng tương đương với hoạt động của CPU đa luồng. 1.190 suy luận / J được đo ở 0,6V, tương ứng với 13,6Top / s / W cho Inception-V3.
Trên mỗi khu vực, chip Samsung đạt 2,69Top / s / mm2 và 114 suy luận / s / mm2.
Về khía cạnh nhỏ bé, Đại học Công nghệ Nanyang từ Singapore và Đại học Columbia đã xem xét trí tuệ nhân tạo vi năng lượng. Nanyang đã trình bày một hệ thống nhận dạng cử chỉ tay trong thời gian thực cho các thiết bị có thể đeo và IoT, hoạt động bằng cách kiểm tra dữ liệu cạnh từ hình ảnh VGA (640x480x8bit), tiếp theo là bộ phân loại nhỏ gọn kết hợp để nhận dạng cử chỉ tĩnh và một bộ phân tích trình tự có khả năng chịu lỗi để nhận dạng cử chỉ động .
Chip 65nm 1,5mm2 có thể nhận dạng 24 cử chỉ động với độ chính xác trung bình là 92,6%, tất cả đều cho 184μW ở 0,6V.
Bộ xử lý của Columbia là công cụ phát hiện từ khóa luôn chạy 65nm được thiết kế để hoạt động trong điều kiện nhiễu nền. Huấn luyện không phụ thuộc vào tiếng ồn thông thường hơn - huấn luyện với nhiều mức độ và loại tiếng ồn khác nhau - sẽ dẫn đến một mạng lưới thần kinh quá lớn, vì vậy nhóm đã sử dụng một sơ đồ lấy cảm hứng từ sinh học đơn giản hơn gọi là 'bình thường hóa năng lượng chia'. Quá trình xử lý được trải rộng trên một chip "chiết xuất tính năng âm thanh chuẩn hóa" lấy tín hiệu âm thanh từ micrô và tạo ra các tính năng được mã hóa tốc độ tăng đột biến (cho 109nW) và chip phân loại mạng thần kinh tăng đột biến.
Đối với công suất 570nW, hệ thống hai chip đạt độ chính xác 89 - 94% trên tỷ lệ tín hiệu trên nhiễu từ -5 đến 20dB với bốn loại nhiễu khác nhau (bộ dữ liệu HeySnips). Về khả năng, độ chính xác là 96,5% khi tìm kiếm một từ khóa hoặc 90,2% khi tìm bốn từ khóa.
Chip lớp mỏng ISSCC 9.1 Một chip AI 4 nhân 7nm với đào tạo FP8 lai 25,6Tclops, suy luận INT4 102,4Tops và điều chỉnh khối lượng công việc nhận biết
Chip lớp mỏng ISSCC 9.5 Một đơn vị xử lý thần kinh nhận biết tính năng 6k-MAC-bản đồ-độ thưa thớt trong SoC di động hàng đầu 5nm
Chip lớp mỏng ISSCC 9.7 Một hệ thống nhận dạng cử chỉ tay theo thời gian thực 184µW với các bộ phân loại siêu nhỏ kết hợp cho các thiết bị đeo thông minh
Chip lớp mỏng ISSCC 9.9 Một bộ chiết xuất tính năng âm thanh 109nW chịu được nhiễu nền và biến đổi quy trình dựa trên chuẩn hóa năng lượng chia miền tăng đột biến cho thiết bị phát hiện từ khóa luôn bật.